
Microsoft just cancelled Claude Code licenses across its biggest engineering division. Windows, Microsoft 365, Outlook, Teams, Surface. Engineering usage had outrun the budget. A few weeks later Microsoft launched its own coding model that solves harder problems using up to 60% fewer tokens than Claude Haiku 4.5. The two announcements are the same story.
That story is showing up everywhere. Companies are bleeding cash on AI. Uber capped employee spending after draining its budget in four months. Salesforce froze engineering hires while staring down a $300 million bill for Anthropic tokens. GitHub Copilot is moving from a flat subscription fee to consumption-based billing. Anthropic adjusted Claude Code pricing. Google Gemini 3.5 Flash tokens cost three times more than the previous version. GPT-5.5 prices have surged.
AI providers are pushing consumption-based pricing right as their tools get hungrier. New models and system updates keep burning through more tokens per run just to process a request. This makes the standard way of calculating AI costs completely broken. Right now, most buyers look at a provider’s pricing page, check the cost per 1,000 tokens, and pick the cheapest option. But that base price means nothing if the tool is inefficient.
Instead of looking at flat rates, companies need to calculate the actual cost per result. This means tracking the total number of tokens a model uses to finish a task correctly, and then multiplying that usage by the provider’s token rate. The industry has a name for the broader waste pattern: tokenmaxxing. Most coverage uses it for the employee side. Amazon’s internal AI leaderboard made headlines in May after staff were caught burning tokens to climb the rankings rather than solve real problems. The model side counts too. Some models pad their answers with long, wordy explanations just to reach the right output. Both versions show up on the same invoice. If a cheap model needs 3,000 tokens to fix a coding bug but a premium model needs only 500, the cheap model actually costs you more.
Independent testing proves how big this gap is. Artificial Analysis measures a metric called the Intelligence Index against the actual cost to run those tests. As venture capitalist Tomasz Tunguz points out, GPT-5.5 and Claude Opus 4.8 score almost exactly the same on basic intelligence tests. Yet, running the standard benchmark costs $3,357 on GPT-5.5 and $4,685 on Claude Opus 4.8. You get the exact same answer, but one option costs 40% more to run.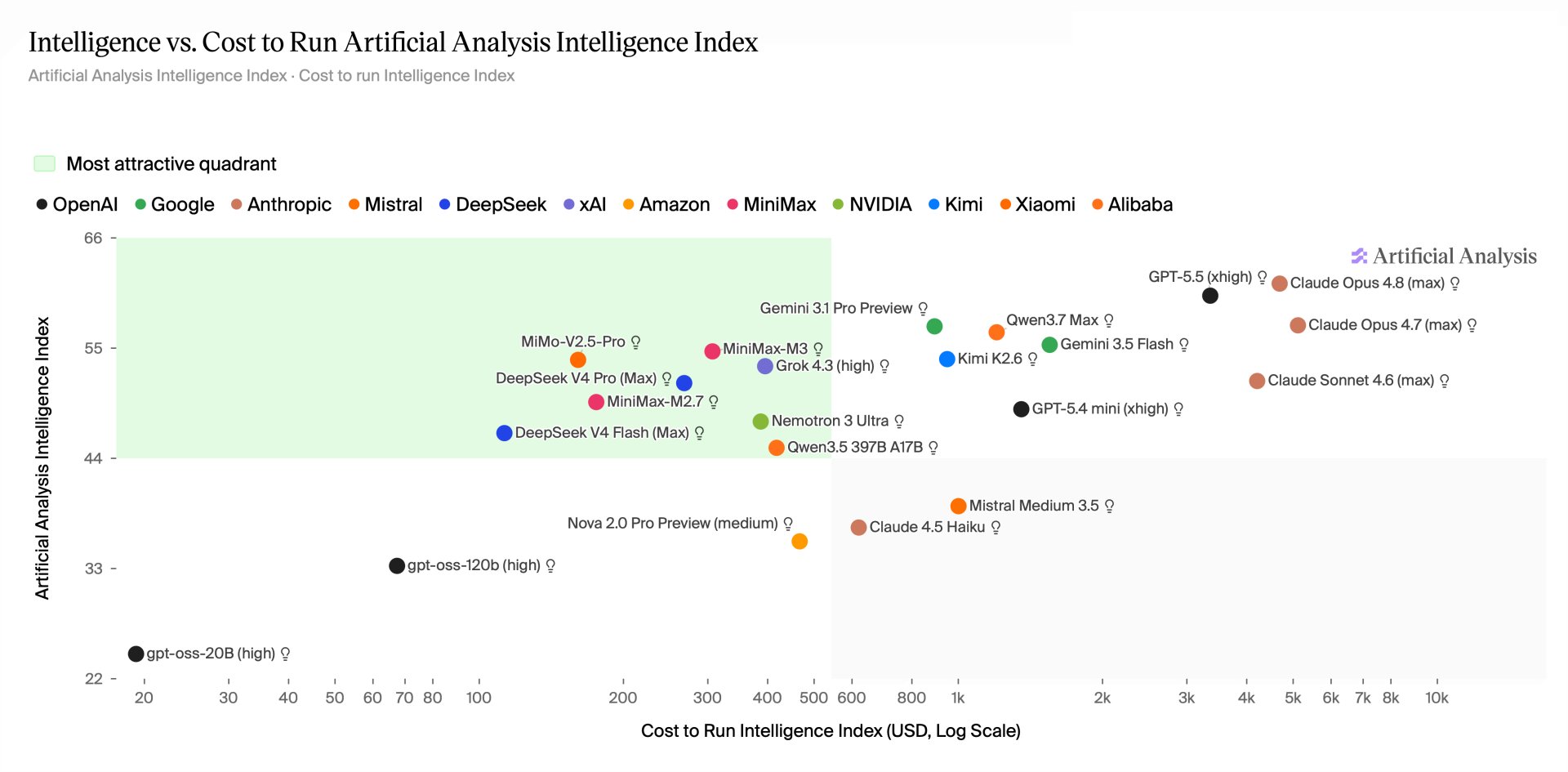
The industry is starting to catch on. Microsoft recently added average token usage to its model spec sheets. Their new MAI-Code-1-Flash tool focuses on value per token rather than chasing high benchmark scores. It adapts to the request, giving short answers for simple questions and spending more tokens only when a task is complicated. Microsoft notes this approach allows the model to solve harder problems using up to 60% fewer tokens than competitors like Claude Haiku 4.5.
How aiLab approaches model selection in production
When we deploy AI for clients at aiLab, the first lever is the simplest one: pick the right model for the job. That means right size and right skills. A small, focused model often beats a frontier model on a narrow task, because the frontier model is paying for capability it does not need on that specific job. Mixture-of-experts architectures push this idea further. Inside one model, only the relevant expert sub-network activates for each token, so the model behaves like a smaller specialist on every actual call. Pick the model whose active path matches the work and you stop paying for capability you are not using.
The second lever is measurement discipline. Token counts come from the application layer, not the vendor dashboard, because routing logic and retries inflate the real bill in ways the dashboard does not show. “Outcome” gets defined upfront. A closed support ticket. A passing code review. An approved invoice line. The denominator has to be meaningful, not just “the model returned something.”
The third lever is routing. A cheap fast model handles the bulk of the volume. A premium model gets called only on the cases the cheap one cannot finish confidently. The routing decision itself can run on rules or on a small classifier, both of which are cheaper than the work they triage. On a recent customer-support deployment we ran the routing first-pass with a small model, escalating a minority of tickets to a larger one. Total cost per ticket came in well below the all-premium baseline, with no measurable drop in resolution quality.
Raw brainpower is no longer the only metric that matters. Businesses have to look at the overall cost, how tasks are routed, and which model is picked for a specific job. AI tools are now competing on dollars per outcome. To keep budgets under control, teams need to stop looking at flat pricing pages and start measuring what it actually costs to close a support ticket, finish a code review, or ship a feature.
Share this article


