
Anthropic’s new essay on recursive self-improvement can be read as a warning about the future. That is not the most useful reading for builders.
The development signal is more concrete: AI has moved from autocomplete, to coding assistant, to agentic worker that can write files, run code, test changes, investigate incidents, and hand work to other agents. The interesting question is not whether this sounds dramatic. The interesting question is what software teams should change because of it.
Anthropic’s data gives a useful look at where development work is heading. It should not be copied directly into every company forecast. Anthropic is a frontier AI lab, and the numbers come from its own internal environment. The company also has wider context around it: on 1 June 2026, Anthropic confidentially submitted a draft S-1 to the SEC, which is a step toward a possible IPO. That does not make the essay wrong, and it does not mean the data is inflated. It does mean readers should treat the framing with some caution. Anthropic has a clear incentive to show that its internal AI systems are changing the economics of software work. The numbers are useful signals from one unusual frontier lab, not a neutral industry average.
The useful part of the Anthropic data
The first signal is task length. Anthropic cites METR’s finding that the length of tasks AI systems can reliably complete on their own has been doubling roughly every four months. In March 2024, Claude Opus 3 could complete software tasks that took humans about four minutes. A year later, Claude Sonnet 3.7 was handling tasks closer to an hour and a half. A year after that, Claude Opus 4.6 was managing 12-hour tasks.
That change matters more than benchmark points. A model that can handle a four-minute task is a helper. A model that can stay useful across a 12-hour task starts to look like a junior worker with patience, tools, and no context-switching cost.
The second signal is production code. Anthropic says that as of May 2026, more than 80% of the code merged into its own codebase was authored by Claude. The company also says the typical engineer was merging about 8x as much code per day in the second quarter of 2026 as in 2024.
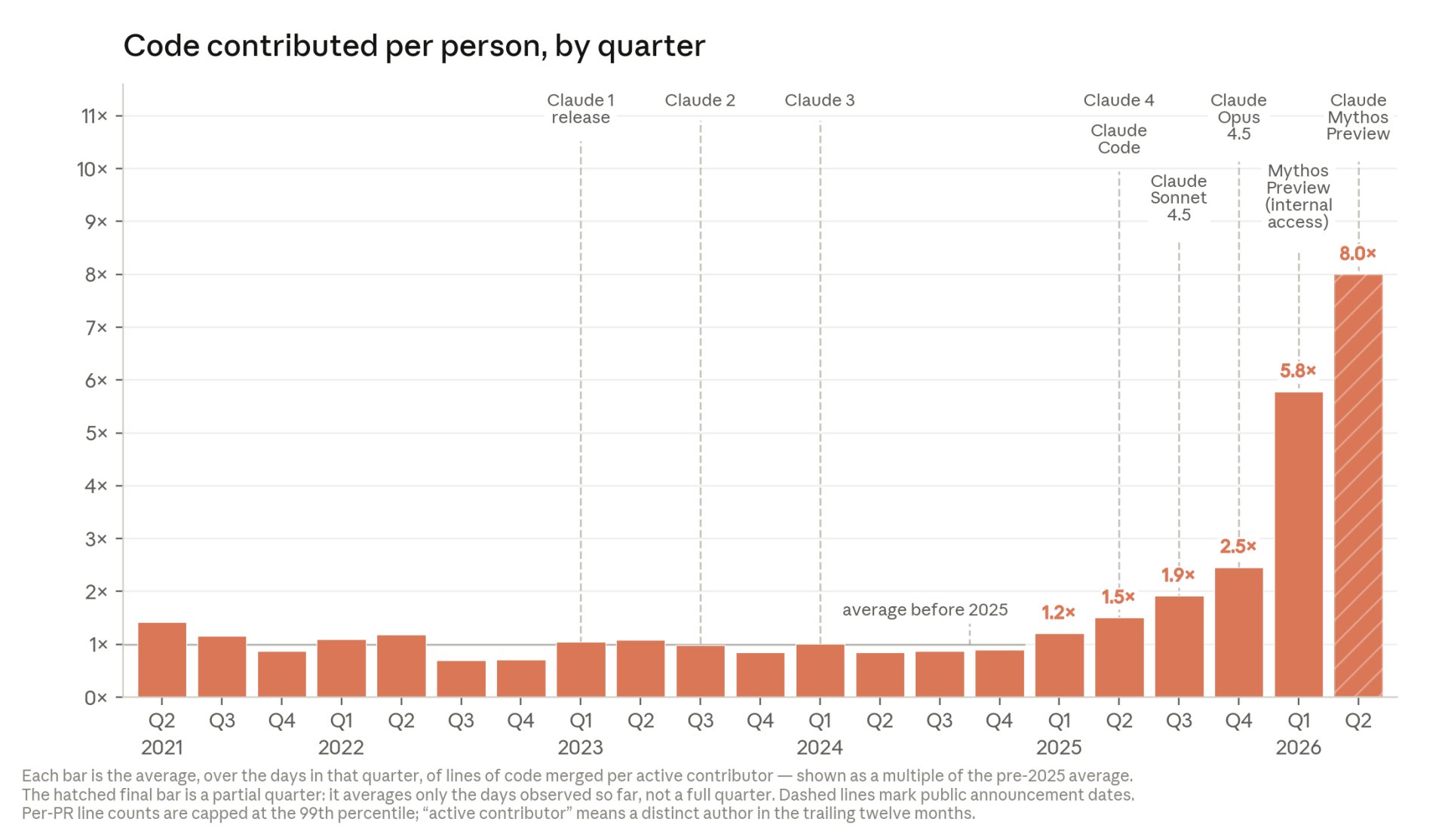
Source: Anthropic, “When AI builds itself”. Lines of code are a rough quantity signal, not a clean productivity measure.
Lines of code are a rough measure. Anthropic says that directly. More code does not automatically mean better software. But it does tell us where the pressure will move. If agents can produce code faster than humans can review, understand, and safely ship it, review becomes the bottleneck.
The third signal is quality. Anthropic reports that Claude’s success rate on its most open-ended coding tasks reached 76% in May 2026, up 50 percentage points in six months. It also says automated Claude review, if run across past changes, would have caught roughly a third of the bugs behind previous incidents on claude.ai before they reached production.
That is a bigger shift than “AI writes code.” The loop is becoming: AI writes the code, AI reviews the code, humans set the target, decide what matters, and take responsibility for the result.
The real bottleneck is no longer implementation
Anthropic makes one point that should sit on every engineering roadmap: once models can run experiments, the question moves from “can we do this?” to “which experiment is worth running?”
That is already visible in normal product work. The easy win with AI coding tools is faster implementation. The harder win is better direction. A team can now generate three approaches to a feature, rewrite a service, add tests, migrate a dependency, and build internal tools much faster than before. But the team still has to know which of those things deserves attention.
This is where the development role changes. Engineers become less like typists and more like system designers, reviewers, and operators of agent workflows. The valuable skill is not “can you produce the patch?” It is “can you define the right patch, constrain the work, judge the output, and notice when the agent is confidently wrong?”
What this predicts for software teams
The first prediction: code review becomes a production system.
Review will not stay as a human scanning a pull request at the end. It will become a layered process: static checks, test generation, security review, architecture rules, style rules, dependency checks, runtime simulation, and finally human judgment. The human reviewer will spend less time finding syntax-level mistakes and more time asking whether the change should exist at all.
The second prediction: specifications become more valuable than tickets.
Agents perform best when the goal, constraints, and success checks are clear. A weak ticket produces a large vague diff. A strong specification gives the agent a narrower path and gives the reviewer a way to judge the result. Teams that write better specs will get better agent output, even if they use the same model as everyone else.
The third prediction: technical debt splits in two directions.
Anthropic gives a useful example: Claude shipped more than 800 fixes in April 2026 that reduced one class of API errors by a factor of one thousand. The engineer overseeing it estimated the same work would have taken a human four years. That is the positive version of agentic maintenance: long-deferred cleanup becomes cheap enough to do.
The negative version is just as real. If agents produce more code than the organization can understand, technical debt can grow faster than before. The difference is not the model. The difference is whether the team has tests, architecture boundaries, ownership, and review gates strong enough to absorb the volume.
The fourth prediction: small teams get wider reach.
Anthropic describes a future where each employee sits on top of a pyramid of agents. That is already the right mental model for builders. A five-person team will increasingly look like a much larger team if each person can delegate research, code, testing, documentation, data cleanup, and migration work to agents. The headcount advantage moves from “how many people can we hire?” to “how much useful work can each person safely supervise?”
How we would apply this in a real development team
The wrong response is to give an agent broad repository access and hope the productivity numbers appear. The right response is to build an agent-ready development loop.
Start with narrow work types. Good first candidates are regression fixes, test coverage, internal tooling, data migration scripts, dependency upgrades, documentation drift, and small refactors with clear tests. These tasks have enough structure for an agent to be useful and enough value to matter.
Then build the control layer around them. Each loop needs a written task format, repo context, test commands, acceptance criteria, review rules, logging, and a way to measure whether the shipped result actually worked. Without that layer, the team is not automating development. It is creating a faster way to produce review burden.
The goal is not to remove engineers from the loop. The goal is to move engineers to the highest-leverage part of the loop: defining the work, checking the result, deciding what to run next, and improving the system that creates the work.
The practical roadmap
For teams planning around this shift in 2026, the roadmap is straightforward.
- Make the codebase legible. Agents need structure. Clear module boundaries, setup instructions, test commands, and architecture notes pay back faster when agents are doing more work.
- Strengthen tests before widening access. If an agent can change more code than a human, the test suite becomes a safety rail, not a nice-to-have.
- Separate task classes. A dependency upgrade, a bug investigation, and a product feature need different prompts, tools, permissions, and review depth.
- Measure outcomes, not code volume. Track cycle time, escaped defects, review time, rollback rate, and cost per accepted change. Lines of code are a weak proxy.
- Protect judgment time. If senior engineers spend their day reviewing agent-generated noise, the system failed. The workflow should reduce low-value work and protect time for architecture, product judgment, and risk decisions.
This is the development-focused reading of Anthropic’s piece. Recursive self-improvement may or may not arrive soon. But a quieter version is already here: AI systems are improving the work of building AI systems, and the same pattern is moving into normal software teams.
The next advantage will not come from asking models to write more code. Everyone will be able to do that. The advantage will come from building development systems where agents can do useful work, humans can judge that work quickly, and the organization can find the next bottleneck before it becomes the limiter.
Read Anthropic’s original essay: When AI builds itself
Read Anthropic’s S-1 announcement
Share this article


